Apache Flume NG
在大数据行业,flume 作为一款常用的日志采集工具被广泛地应用到各个实时或离线的分析系统中,各种技术文章也基本能解释清楚其基础原理。但很多时候的应用需求希望能够简化其使用,我们就需要对其进行功能上的扩充,Flume 的灵活性也就给了我们很大的帮助。
网络上千篇一律地介绍了 flume 的基本工作原理,我就简单地搬个图过来,具体的大家可以自行搜索先了解了解,当然我们也会在接下来的描述中介绍到其部分原理。


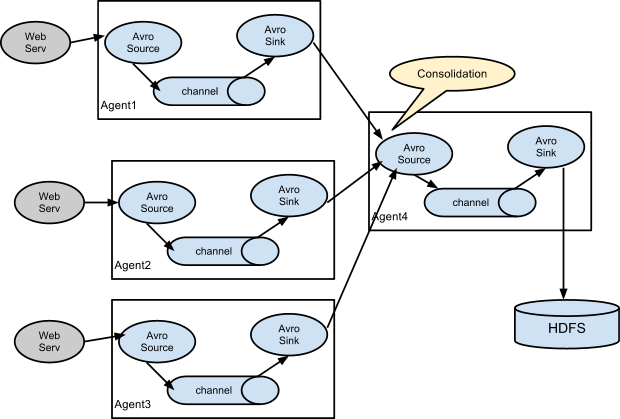
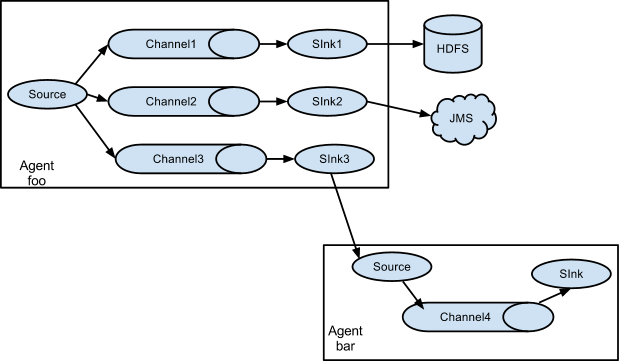
从图中可以很容易地看出,flume NG(后续简称 flume)分为三大块:source, channel, sink,source 负责从数据源获取数据,将数据生产到 channel,channel 作为一个消息队列的形式,最后由 sink 消费掉 channel 中的数据。这种形式就使得其相当地容易进行组合,用户可以将其中任意一个环节设置成其需要的模块:获取不同的数据源、选择不同的消息队列、落地到不同的存储。
从源码层来看,三者均继承自 LifecycleAware, NamedComponent 这两个接口。
需要实现 LifecycleAware 的 start、stop 以及 getLifecycleState 三个方法,实现 NamedComponent 的 setName 和 getName 方法。在 flume 启动的时候,主函数 org.apache.flume.node.Application 会将配置文件或 zookeeper 中的参数加载到参数对象中,然后调用 setName 以及 start 方法。
在初始化过程中,配置参数的同时,会调用继承自 AbstractConfigurationProvider 的类,然后根据 LifecycleAware 的子类是 Source、Channel 或是 Sink 来调用其中的其他的方法。
看源码:
1.source
public interface Source extends LifecycleAware, NamedComponent {
/**
_ * Specifies which channel processor will handle this source's events._
_ *_
* @param channelProcessor
*/
public void setChannelProcessor(ChannelProcessor channelProcessor);
/**
_ * Returns the channel processor that will handle this source's events._
_ */_
public ChannelProcessor getChannelProcessor();
}
2.Channel
public interface Sink extends LifecycleAware, NamedComponent {
/**
* <p>Sets the channel the sink will consume from</p>
* @param channel The channel to be polled
*/
public void setChannel(Channel channel);
/**
* @return the channel associated with this sink
*/
public Channel getChannel();
/**
* <p>Requests the sink to attempt to consume data from attached channel</p>
* <p><strong>Note</strong>: This method should be consuming from the channel
* within the bounds of a Transaction. On successful delivery, the transaction
* should be committed, and on failure it should be rolled back.
* @return READY if 1 or more Events were successfully delivered, BACKOFF if
* no data could be retrieved from the channel feeding this sink
* @throws EventDeliveryException In case of any kind of failure to
* deliver data to the next hop destination.
*/
public Status process() throws EventDeliveryException;
public static enum Status {
READY, BACKOFF
}
}
3.Sink
public interface Sink extends LifecycleAware, NamedComponent {
/**
* <p>Sets the channel the sink will consume from</p>
* @param channel The channel to be polled
*/
public void setChannel(Channel channel);
/**
* @return the channel associated with this sink
*/
public Channel getChannel();
/**
* <p>Requests the sink to attempt to consume data from attached channel</p>
* <p><strong>Note</strong>: This method should be consuming from the channel
* within the bounds of a Transaction. On successful delivery, the transaction
* should be committed, and on failure it should be rolled back.
* @return READY if 1 or more Events were successfully delivered, BACKOFF if
* no data could be retrieved from the channel feeding this sink
* @throws EventDeliveryException In case of any kind of failure to
* deliver data to the next hop destination.
*/
public Status process() throws EventDeliveryException;
public static enum Status {
READY, BACKOFF
}
}
官方提供了一些可用的实现
Source
- AvroSource 基于 Socket 协议和 json 方式序列化的服务,用户可以配置可信的 ip 或者 hostname 来决定客户端发送的数据是否接收,安全机制上,还能设置 ssl 的验证,常用于多地机房的数据中转。
- ExecSource
- MultiportSyslogTCPSource
- NetcatSource
- NetcatUdpSource
- SequenceGeneratorSource
- SpoolDirectorySource 常用的对目录文件数据的输入
- StressSource
- SyslogTcpSource
- SyslogUDPSource
- ThriftSource
- HTTPSource
Channel
- FileChannel 最常使用的方式,对于数据量比较大的系统,内存通道方式很容易产生 OOM,虽然内存方式效率极高,但是仅适用于数据量小,或者落地效率极高的场景。
- JdbcChannel
- SpillableMemoryChannel
- MemoryChannel
- PseudoTxnMemoryChannel
Sink
- HDFSEventSink
- HiveSink 该方式必须是 Hive 的桶表,并且开启了事务(Orc 列存储方式),该方式会调用 HiveEndpoint 来写数据,我接触过的系统大多使用 spark 做数据处理,而该方式的 hive 表通过 jdbc 或者是 orc 的方式均不能正常加载数据到 spark(目前 spark2.2 的 orc 和 hive1.2 的 orc 文件不兼容),所以直接利用 HDFS 更佳。
- IRCSink
- KafkaSink 实时系统常用的,通常情况下,会开一个 Thrift 的 source,或者根据业务的协议自定义一个基于 socket 的服务的 source,通过 interceptor 将上报的字节码数据转换成需要的 json 数据,然后存放到 kafka 中,再到线上利用实时系统做一些数据分发或者实时分析的业务。后续一般也就是从 kafka 读一份存到数据仓库,然后另外几条线都是实时的分析任务。
- AvroSink 该方式相当于开启了一个 Avro 的客户端,将数据发送至 Avro 服务。一般是配合 source 端的 Avro 将数据传递到另外的机房的数据仓库。
- LoggerSink
- NullSink
- RollingFileSink
- ThriftSink
然后大家常用到的一些第三方的实现
Source
- org.keedio.flume.source.SQLSource 这是一个 jdbc 数据源的 source,被大家广泛使用。该 source 会调用 hibernate 的功能块获取 jdbc 数据源的数据,然后转换成 csv 格式的数据(使用的 opencsv),经常会出现一些奇怪的换行符,所以我们在实际使用中替换成 json 的 array 形式表示一行数据,在落地前转换为需要的数据结构。
实际的需求
对于定义好的业务,以现有的对配置文件的形式来指定配置最为稳定,或者以统一的 zookeeper 来管理配置文件。但是对于复杂业务环境,往往官方的东西不足以支撑,所以需要自定义一些特性。
常见的使用方式:
多个数据源的数据结构相同,此时可以通过多个 source 将数据汇总到一个 channel 中,最后由多个 sink 并行地写入到存储中。
一个数据源需要复制多份,用于不同的系统业务,此时由一个 source 分发到多个 channel 中,每个 channel 的数据都是一个相同的副本;再由不同的 sink 输出到不同业务的存储中。
由此可以看出,如果想要产生多个副本,一个数据源可以通过多个 channel 来实现对副本的增加,一个 channel 始终对应一份副本,sink 数量增加相当于提高了数据写入到存储的并行度。多数据源汇总其实意义不大,因为大多数落地后也就汇总了。我们常见的问题:
- 数据源与数据仓库不在同一机房,且数据源只能通过内网访问,系统需要在页面端实现一套业务一个同一配置,数据源采集与落地仓库的采集服务需要自动在可用端口段分配端口用于 avro 的交换方式,原则上分配了两个采集,需要人员在两台机器上配置不同的参数,维护的时候需要先停止输入端的服务,再停止落地端的服务,相当麻烦。如果由统一的调度自动获取可用端口,分配给输出源的采集服务,自动生成数据桥接的配置,然后由服务分发给两端的服务,将极大简化任务的调度。
-
很多时候由于系统资源不足,不足以同时启动多个采集任务,需要分时间段或根据数据采集情况随时启停某些采集任务。单一的定时任务控制不一定能满足判断启停条件,某些时候停止标识需要配合监控到的一定时间段内的数据流量来触发。
-
多个 flume 任务的管理相对分散,不易于管理(flume 的主函数始终是 Application,查询 agent 需要根据 java 执行的命令来判断,相对复杂)。
Flume RESTful Driver
鉴于常见的使用方式以及存在的一些问题,采用统一的服务对 flume 的 agent 进程进行管理的需求就比较迫切。我根据我们常用的服务简化了一层轻量级的服务,用于对 flume 任务的控制,命名为 Flume RESTful Driver,以下简称 driver。
Driver 采用 spring boot 作为 http rest 服务框架。提供了启动、监控以及停止功能的 rest 请求接口。使用 Spring ApplicationContext(StaticApplicationContext)以 bean 形式寄存每一个用户定义的 agent。我们合理地使用了 bean 的单例模式,保证同一个 agent 只存在一个副本,这样在每一次操作任务的时候保证通过 agentName 就能获取到正确的任务对象,并且获取其配置信息以及 counter 中的监控信息,以 json 方式展示。
Driver 基本原理
-
提交任务,此时需要用户传递 requestbody,包含 agentName,source(包括其对应的一个 interceptor),channels,sinks 的信息。服务接收到 json 对象后,根据 agentName 创建 spring bean 对象,再根据 json 对象初始化为 flume 的配置参数,然后传递给 bean,最后调用 bean 的方法创建 flume 的 agent,此时 agent 被启动。
-
查询指定的 agent 信息,服务接收到 agentName 之后,向 ApplicationContext 获取对象,然后获取其中保存的参数值,再由 jmx 对象中抽取到 flume 中对应的 counter 信息。最后将信息整合后返回给用户。
-
查询 agent 列表,服务接收到请求后,从 ApplicationContext 将所有 bean name 以 json 形式返回给用户。
-
停止任务,用户指定需要停止的 agentName,服务从 ApplicationContext 获取到对应的 bean,然后调用对象中的 stop 方法,会立即调用 Application 的 stop 方法,停止 jmx 监控,然后将各个 LifecycleAware 停止。最终再移除 ApplicationContext 中对应的 bean 对象。
项目地址:
https://github.com/matrixzoo/flume-restful-driver
安全性的问题
Spring boot 本身提供了大量的成熟的组件,目前项目没有增加任何安全验证,后续会在项目中更新。实际的业务中,通常会使用 spring-boot-starter-security 模块,在配置文件中配置一个可用的用户密码作为一种简单的安全验证。项目中大多数情况下直接使用硬件防火墙对 ip 做限制了,这一层其实也可以不加。这个需要具体看实际的业务情况。
driver 项目的一些计划
我们在大多数的项目中都采用了一个统一的调度管理界面,但是定制化程度较高,不适用于普遍情况,未来会扩展加入一个统一调度的服务,但是要权衡大多数的使用场景,而且最好是轻量级的,易于做二次开发的。
目前 flume 提供的组件只能说适应了大部分情况下数据从传统数据库到大数据平台的,但其架构不失为一个良好的 etl 工具,后期会拓展一些我认为常用的自定义的 source 以及 sink。
同时也希望有志同道合的朋友加入到该项目的开发中,拓展一些轻量级的功能。该项目以轻量级、易拓展为原则。